

Apresentação
Uma das razões da existência de bugs em programação tem a ver com a dificuldade em manter actualizadas as várias versões e na necessidade que por vezes existe de voltar a uma versão anterior porque desistimos e queremos mudar de “caminho”. Esta dificuldade é ainda maior quando temos uma equipa a trabalhar no mesmo projecto.
O controlo de versão é um sistema que regista as mudanças feitas num ficheiro ou num conjunto de ficheiros ao longo do tempo de forma que se possam recuperar versões específicas. Sendo a utilização mais comum em ficheiros de código fonte sob controlo de versão, pode ser usado com praticamente qualquer tipo de ficheiros num computador.
Quando se pretende manter no desenvolvimento de um projecto, todas as versões por forma a, em qualquer altura, se poder reverter para uma versão anterior, o uso de um sistema de controlo de versão (VCS), permite reverter ficheiros ou o projecto completo para um estado anterior, comparar alterações e identificar quem as efectuou, detectar mais facilmente bugs e recuperar ficheiros perdidos ou estragados.
Para lidar com a necessidade de controlar o trabalho de vários programadores a utilizar diversos sistemas, foram criados sistemas centralizados de controlo de versão (CVSC). Estes sistemas possuem um ou vários servidores centrais que contêm todos os ficheiros que podem ser “resgatados” pelos vários “clientes”.
As desvantagens prendem-se com a possibilidade de avarias e a dependência de todos de um único repositório, que se não existirem backups adequados poderá originar perdas importantes de trabalho e produtividade.
Para combater estas desvantagens, foram criados os sistemas de controlo de versão distribuídos (do qual o GIT é um exemplo), em que os clientes não fazem apenas cópias das últimas versões dos ficheiros, eles são cópias completas do repositório. Assim, se um servidor falha, qualquer um dos repositórios dos clientes pode ser copiado de volta para o servidor para restaurá-lo.
Criado pela necessidade dos programadores do Kernel do Linux em substituir o Bitkeeper que deixou de ser gratuito, o GIT foi evoluindo ao longo do tempo para um sistema fácil de usar, mantendo as características iniciais de velocidade, design simples, suporte robusto e não linear (milhares de ”ramos” paralelos), totalmente distribuído e com capacidade para lidar eficientemente com grandes projectos.
Os sistemas tradicionais de controlo de versão armazenam os dados como um conjunto de ficheiros e suas alterações ao longo do tempo. O GIT, pelo contrário, trata os dados como um conjunto de “snapshots” (imagem de algo em determinado instante como numa foto), isto é, cada vez que se salva ou consolida (commit) o GIT, como se tirasse uma foto de todos os ficheiros naquele momento, armazena uma referência para essa captura. Para ser eficiente não armazena novamente os ficheiros não alterados, apenas um link para o ficheiro idêntico anteriormente armazenado. Esta é a distinção importante do GIT relativamente aos outros sistemas e faz com que o GIT se comporte como um mini sistema de ficheiros com poderosas ferramentas por cima.
A maior parte das operações no GIT precisam apenas de recursos e ficheiros locais para operar, o que representa ganhos em termos de velocidade e disponibilidade. Apesar disso, tudo no GIT tem “checksum” (verificação de integridade) pelo que é impossível mudar o conteúdo de algum ficheiro ou directório sem que o GIT tenha conhecimento.
O GIT faz com que os ficheiros estejam sempre num de três estados: - modificado, preparado e consolidado. Modificado, quando um ficheiro sofreu alterações e ainda não foi consolidado, preparado se, depois de uma alteração foi marcado para seguir no próximo “commit” (consolidação) e consolidado se estão seguramente guardados na base de dados locais. Esta filosofia faz com que existam no GIT três secções, a directoria de trabalho, a área de transferência e a directoria GIT (repositório).
A directoria de trabalho é o local do disco onde se encontram os dados obtidos da base de dados comprimida do repositório (directoria GIT) de forma a poderem ser usados e alterados. Área de preparação é por norma um único ficheiro que armazena informação sobre o que vai seguir na próxima consolidação (é também referido como índex).
O workflow básico do GIT ( Fig. 6) pode ser descrito assim:
- Modificação ficheiros na directoria de trabalho.
- Selecção dos ficheiros, adicionando snapshots deles para a área de preparação.
- Fazer um commit, que leva os ficheiros tal qual eles estão na área de preparação e os armazena permanentemente na directoria GIT.[4]
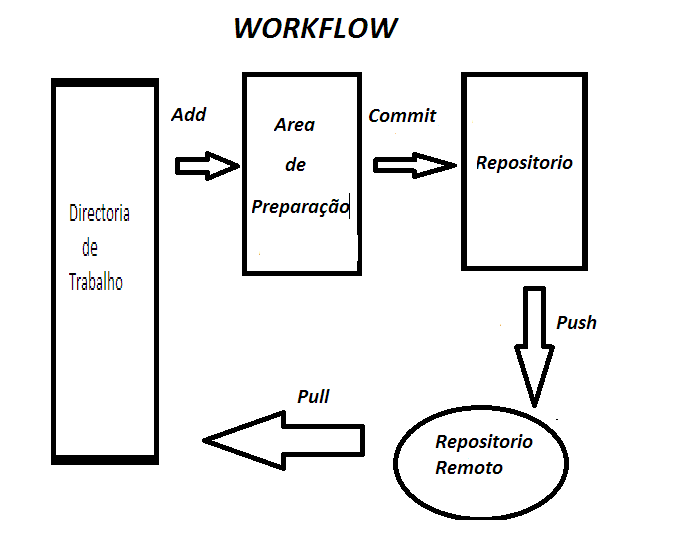
Fig. 6- GIT workflow
Configuração
Estão disponíveis várias versões de GIT consoante o sistema operativo utilizado. Porque estes são os SO utilizados na empresa estudei a instalação em Windows e em CentOS.
Windows
Instalar o cliente Git no Windows é muito fácil. O projecto msysgit tem um dos procedimentos mais simples de instalação. É necessário fazer download e executar o ficheiro exe do instalador a partir da página do GitHub:
https://msysgit.github.com
Concluída a instalação, ficam disponíveis, uma versão command line (linha de comando, (Fig. 7) que inclui um cliente SSH) e uma versão com interface gráfica (Fig. 8).
Aqui encontra-se um manual de instalação passo a passo
Fig. 7- GIT Command line
Fig. 8- GIT GUI
CentOS
No Linux, o GIT pode ser instalado através de um instalador binário, usando a ferramenta de gestão de pacotes, no caso do CentOS, utilizei o yum:
# yum install git-core
Aqui encontra-se um manual de instalação passo a passo.